4.2.3. Sample Project: Custom Data Service¶
The sample code for this service is in the samples directory in the Pyslet distribution: fsodata.py
This project demonstrates how to construct a simple OData service based on a custom EntityContainer class. It also demonstrates how to handle media streams in your own data sources.
Although OData is often talked about as the ODBC of the web there is no reason why your data has to be in a database format to be exposed by OData...
4.2.3.1. Step 0: Create the DAL implementation¶
If your data source is in a general form then you will want to create
general classes dervied from
pyslet.odata2.core.EntityCollection and
pyslet.odata2.core.NavigationCollection. For example,
suppose you want to expose data stored in a ‘Unix’ database accessed
using one of Python’s dbm modules. You could write a general
implementation that maps this DAL API to the dbm interface. This is
similar to the approach taken with the SQL classes, they are written
using Python’s DB API enabling a wide variety of SQL databases to be
exposed through OData with little or no extra work required for a
specific data set.
On the other hand, if your datasource is fairly specific to a particular application you might create specific implementations of these classes that are tied to the entities in your model.
In this project, we’ll take the latter approach and so defer discussion of the implementation details until we’ve constructed the model.
4.2.3.2. Step 1: Creating the Metadata Model¶
For small amounts of data, the basic OData classes already supplied do almost everything you need. In this example we’ll expose information about the files and directories in a designated part of the file system for an application like a blog or a simple file sharing site. We’ll assume that there aren’t too many files and that walking the tree is a relatively painless operation to perform.
As before, we start with our metadata model, which we write by hand. There is just one entity set: Files. It has two navigation properties that are defined by a single parent/child association.
Here’s the model:
<?xml version="1.0" encoding="utf-8" standalone="yes" ?>
<edmx:Edmx Version="1.0"
xmlns:edmx="http://schemas.microsoft.com/ado/2007/06/edmx"
xmlns:m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata">
<edmx:DataServices m:DataServiceVersion="2.0">
<Schema Namespace="FSSchema"
xmlns="http://schemas.microsoft.com/ado/2006/04/edm">
<EntityContainer Name="FS" m:IsDefaultEntityContainer="true">
<EntitySet Name="Files" EntityType="FSSchema.File"/>
<AssociationSet Name="Directories"
Association="FSSchema.Directory">
<End Role="Parent" EntitySet="Files"/>
<End Role="Child" EntitySet="Files"/>
</AssociationSet>
</EntityContainer>
<EntityType Name="File" m:HasStream="true">
<Key>
<PropertyRef Name="path"/>
</Key>
<Property Name="path" Type="Edm.String" Nullable="false"
MaxLength="1024" Unicode="false" FixedLength="false"/>
<Property Name="name" Type="Edm.String" Nullable="false"
MaxLength="255" Unicode="true" FixedLength="false"
m:FC_TargetPath="SyndicationTitle"
m:FC_KeepInContent="true"/>
<Property Name="isDirectory" Type="Edm.Boolean"
Nullable="false"/>
<Property Name="size" Type="Edm.Int32" Nullable="true"/>
<Property Name="lastAccess" Type="Edm.DateTime"
Nullable="false" Precision="3"/>
<Property Name="lastModified" Type="Edm.DateTime"
Nullable="false" Precision="3"
m:FC_TargetPath="SyndicationUpdated"
m:FC_KeepInContent="true"/>
<NavigationProperty Name="Files"
Relationship="FSSchema.Directory" FromRole="Parent"
ToRole="Child"/>
<NavigationProperty Name="Parent"
Relationship="FSSchema.Directory" FromRole="Child"
ToRole="Parent"/>
</EntityType>
<Association Name="Directory">
<End Role="Parent" Type="FSSchema.File"
Multiplicity="0..1"/>
<End Role="Child" Type="FSSchema.File" Multiplicity="*"/>
</Association>
</Schema>
</edmx:DataServices>
</edmx:Edmx>
I’ve added two feed customisations to this model. The last modified date of the file will be echoed in the Atom ‘updated’ field and the file’s name will become the Atom title. This will make my OData service more interesting to look at in a standard browser.
Finally, we want to actually download these files so I’ve added the HasStream attribute to the EntityType declaration. The idea is that using the $value path option in the URL will allow you to download the contents of the file.
As before, we’ll save the model to a file and load it when our script starts up. This model is fsschema.xml in the samples directory.
4.2.3.3. Step 0: Revisited¶
Now we have our metadata model specified we can start implementing the classes that will enable it. The keys in our entities are pseudo-paths to the files within a special directory using ‘/’ as a separator, for example ‘/dirA/dirB/file.txt’.
We start with a constant to specify the BASE_PATH and two functions, one that turns our path ‘keys’ into file-system absolute paths and one that reverses the transformation. I won’t repeat the code for these functions here as they can be found in the sample code under the names fspath_to_path and path_to_fspath, but their main job is to ensure that symbolic links and all files and directories with names starting ‘.’ are hidden from the service and that no nefarious OData queries can circumvent the restrictions on the exposed directory.
Given an absolute file system path we can now write a function that will
fill in the details for an entity. Notice the last thing it does is set
the entity’s exists flag to
True indicating that the entity represents a real object in our exposed
directory:
def fspath_to_entity(fspath, e):
path = fspath_to_path(fspath)
e['path'].set_from_value(path)
if path == '/':
e['name'].set_from_value('/')
else:
e['name'].set_from_value(path.split('/')[-1])
if os.path.isfile(fspath):
e['isDirectory'].set_from_value(False)
try:
info = os.lstat(fspath)
e['size'].set_from_value(info.st_size)
e['lastAccess'].set_from_value(info.st_atime)
e['lastModified'].set_from_value(info.st_mtime)
except IOError:
# just leave the information as NULLs
pass
elif os.path.isdir(fspath):
e['isDirectory'].set_from_value(True)
else:
raise ValueError
e.exists = True
Armed with this utility function we derive a class from
pyslet.odata2.core.EntityCollection and bind it to our metadata
model when the script starts up. We’ll look at the details of this class
later but let’s start with the declaration:
import pyslet.odata2.core as odata
class FSCollection(odata.EntityCollection):
""" this is our custom collection class
... more details below"""
Let’s look at the first part of the load_metadata function which is called on script start-up:
import pyslet.odata2.metadata as edmx
def load_metadata(
path=os.path.join(os.path.split(__file__)[0], 'fsschema.xml')):
"""Loads the metadata file from the script directory."""
doc = edmx.Document()
with open(path, 'rb') as f:
doc.Read(f)
# next step is to bind our model to it
container = doc.root.DataServices['FSSchema.FS']
container['Files'].bind(FSCollection)
# ... more initialisation stuff here
The critical step here is the last line where we bind our custom collection class to the ‘Files’ entity set. From this point on, calls to the DAL API for the File entity set will be routed to our collection class, not the default implementation. What do we need to do to handle them?
4.2.3.3.1. Writing our Custom Entity Collection¶
The basic pyslet.odata2.csdl.EntityCollection class documents
the key methods we must override. Our implementation is made a little
simpler because we don’t need to override the __init__ method. In fact,
it is enough to override just a single method to get our custom provider
working: itervalues. There’s a catch though, itervalues must iterate
through all the entities in the collection honouring any filter, ordering
and expand rules that are in effect. This sounds like a lot of work but
the basic implementation has helper methods that can be used to wrap a
simpler implementation.
We start by defining a generator function that yields all the entities in the collection, in no particular order:
def generate_entities(self):
"""List all the files in our file system
The first item yielded is a dummy value with path /"""
e = self.new_entity()
e['path'].set_from_value('/')
e['name'].set_from_value('/')
e['isDirectory'].set_from_value(True)
e.exists = True
yield e
for dirpath, dirnames, filenames in os.walk(BASE_PATH):
for d in dirnames:
fspath = os.path.join(dirpath, d)
e = self.new_entity()
try:
fspath_to_entity(fspath, e)
yield e
except ValueError:
# unexpected but ignore
continue
for f in filenames:
fspath = os.path.join(dirpath, f)
e = self.new_entity()
try:
fspath_to_entity(fspath, e)
yield e
except ValueError:
# unexpected but ignore
continue
We use the builtin os.walk generator and the helper function
fspath_to_entity that we defined earlier. Notice how we use the
new_entity() method to
create an instance and then pass it to fspath_to_entity to get it filled
in with the details. The first entity, corresponding to the root of our
exposed directory, is created by hand for simplicity.
We can now use this generator, combined with the wrapper methods defined by the base class for itervalues:
def itervalues(self):
return self.order_entities(
self.expand_entities(self.filter_entities(
self.generate_entities())))
Our generator function is passed to filter_entities which iterates through our generator yielding only the entities that match the filter. Similarly, this filtered iterable is then iterated by the expand_entities method to implement the expand and select rules. Finally, the resulting generator is wrapped by the order_entities method which sorts them according to the orderby rules. This last step does nothing if there is no orderby option in effect but if there is it is a bit wasteful because the iterator will be turned into a list before it is sorted, causing all entities to be loaded into memory. See Big vs Small Data for advice on dealing with this issue.
With itervalues defined our provider should now be working. The navigation properties are not bound yet so they’ll yield nothing but the basic Files feed should be returning all the eligible files in the BASE_PATH directory.
Before we pack up and commit our changes though we need to revisit the
advice in the base class. Although functional, our collection is very
inefficient when someone uses direct key lookup. Essentially, we’re
iterating through the entire collection every time, just to find a
matching key. We SHOULD override
__getitem__() to improve our code:
def __getitem__(self, path):
"""Get just a single file, by path"""
try:
fspath = path_to_fspath(path)
e = self.new_entity()
fspath_to_entity(fspath, e)
if self.check_filter(e):
if self.expand or self.select:
e.Expand(self.expand, self.select)
return e
else:
raise KeyError("Filtered path: %s" % path)
except ValueError:
raise KeyError("No such path: %s" % path)
The code is pretty simple, we convert the path ‘key’ into a full file system path and then return just that entity. Our path_to_fspath method takes care of raising KeyError for us if the path doesn’t correspond to an object that exists in the directory we’re exposing. fspath_to_entity raises ValueError if the file system path turns out not to belong to a regular file or directory so we catch this and raise KeyError there too.
Notice that the value returned by key lookup must still honour any
filter in place. We use the base class method
check_filter to help us
implement this requirement. Similarly for
set_expand.
The final suggestion for improvement is to override the __len__ method in order to provide a more efficient implementation for determining the number of entities in the collection. Unfortunately, in this case we don’t really have a better method than iterating through them all so we skip that part.
4.2.3.3.3. Adding Support for Streams¶
To access the contents of the file we need to implement support for the stream methods on the base collection. These methods are only supported (and needed) on base collections, not on navigation collections. As a result, we’ll add them to our FSCollection class.
To support reading streams you need to support two new methods, read_stream and read_stream_close. These methods are very similar, they just provide different approaches to obtaining the data. read_stream pushes the data by writing it to a file you pass in as a parameter and read_stream_close pulls the stream, returning a generator that iterates over the data and closing the collection when the iteration terminates. This second form is used by the OData server as it is more compatible with the way the WSGI framework expects to consume data.
The stream methods use a very simple class
StreamInfo to return some basic
information about the stream such as the content type, the size and
modification time. The content type is required, everything else is
optional:
def _get_path_info(self, path):
try:
e = self[path]
fspath = path_to_fspath(path)
if os.path.isdir(fspath):
# directories return zero-length data
sinfo = odata.StreamInfo(type=params.PLAIN_TEXT, size=0)
else:
root, ext = os.path.splitext(fspath)
type = map_extension(ext)
modified = e['lastModified'].value
if modified:
modified = modified.with_zone(0)
sinfo = odata.StreamInfo(
type=type,
modified=modified,
size=e['size'].value)
return fspath, sinfo
except ValueError:
raise KeyError("No such path: %s" % path)
This method returns a tuple of the native file system path and the basic information about the stream. For directories, we return a zero-length text/plain stream, for files we use an internally defined map_extension function to look up the file extension in a simple dictionary.
The type is an instance of
pyslet.http.params.MediaType which is a class wrapper
for content types, you can create you own very simply by passing
the type and subtype as strings:
type = params.MediaType('image','gif')
or, if you have untrusted input, by creating an instance from a string:
type = params.MediaType.from_str(
'text/html; name=index.htm; charset="utf-8"')
print type
# prints: text/html; charset=utf-8; name=index.htm
To generate the data we use another private method:
def _generate_file(self, fspath, close_it=False):
try:
with open(fspath,'rb') as f:
data = ''
while True:
data = f.read(io.DEFAULT_BUFFER_SIZE)
if not data:
# EOF
break
else:
yield data
finally:
if close_it:
self.close()
This is a generator method that yields the data in chunks. When the iteration is complete (or destroyed) the collection can be closed and cleaned up automatically by passing True for close_it.
Armed with these two methods we can finish our implementation by providing implementations of the two required methods for media stream support:
def read_stream(self, path, out=None):
fspath, sinfo = self._get_path_info(path)
if out is not None and sinfo.size:
for data in self._generate_file(fspath):
out.write(data)
return sinfo
def read_stream_close(self, path):
fspath, sinfo = self._get_path_info(path)
if sinfo.size:
return sinfo, self._generate_file(fspath,True)
else:
self.close()
return sinfo, []
4.2.3.4. Step 2: Test the Model¶
Testing our model is fairly easy, I loaded a couple of files and a directory into the BASE_PATH and then ran this session from the interpreter:
>>> import fsodata
>>> doc = fsodata.load_metadata()
>>> container = doc.root.DataServices['FSSchema.FS']
>>> collection = container['Files'].OpenCollection()
>>> for path in collection: print path
...
/
/dtest
/tmp.txt
/dtest/tmp.txt
>>> for f in collection.itervalues():
... print f['path'].value, str(f['lastModified'].value)
...
/ None
/dtest None
/tmp.txt 2014-07-29T10:02:21
/dtest/tmp.txt 2014-07-29T10:23:18
>>> info, gen = collection.read_stream_close('/tmp.txt')
>>> info.size
6
>>> str(info.type)
'text/plain'
>>> for data in gen: print data
...
Hello
>>>
4.2.3.5. Step 3: Link the Data Source to the OData Server¶
This step is almost identical to previous examples.
Once the script is running we can test in a browser:
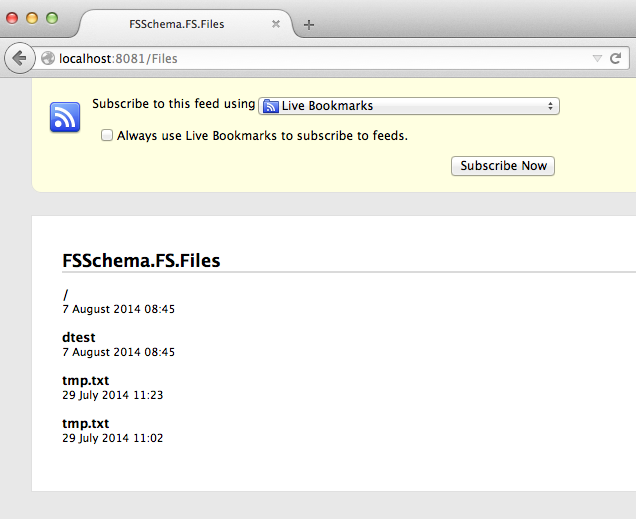
Note
Sharp eyed readers might notice the difference in the time values displayed by the browser and those displayed by the interpreter session above. It is is worth drilling down a little into EDM’s DateTime type to explain. This type has fallen out of favour in OData version 4 but the idea of storing a date time value in an unspecified local time can be meaningful, even if the UTC time it represents varies depending on the location, daylight savings and so on. Indeed, this abstract concept is the one we use in day-to-day life all the time!
In this case, the dates returned by os.stat are elapsed seconds from
the epoch, they are not really expressed in any particular time zone
but bear in mind that their meaning doesn’t change when the clocks
change. This elapsed time is passed directly to the
DateTime class where it is treated
as a ‘unix’ time, in effect ensuring that our lastModified dates
are always stored in UTC (but with no explicit UTC offset).
The catch comes when we publish our information as an Atom feed using OData. There’s a slight oversight in the OData specification here because Atom insists that the updated time of an entry has a date with a timezone. When serialising the entity in Atom format Pyslet assumes that DateTime values are in UTC (which is correct in this case). Firefox, when it renders the feed, is smart enough to convert these updated times into local times for my system (which at the time was running in UTC+01:00).
4.2.3.6. Big vs Small Data¶
Real applications will probably want to expose more data than our simple example. How you do this depends on your data source. The worst case scenario for the implementation shown here is the use of orderby. When orderby is in effect all entities are iterated over and cached in memory before being sorted. A close second is a filter that misses all or most entities in a collection as, again, these filters will cause our method to iterate through all the entities even if iterpage is used to implement restrictions on the amount of data returned.
If your data source has its own query language then you should consider writing something that translates the OData query into the query language of your data source. This is the approach taken by the SQL-based examples.
If, on the other hand, your data source doesn’t have a good query language then you could expose it using a minimal OData implementation (such as the one given here) and then use the same schema to create a SQL-backed service. Pulling the data from your data source through the API and pushing it into the SQL-backed service would be fairly trivial and could be done as a periodic synchronization process. This works even better if you have a last modified field on your entities that you can use to filter out the unchanged ones, as our simple implementation of itervalues won’t cause the collection to be loaded into memory for a filter alone.
Finally, if periodic synchronization is not good enough to reflect the
dynamic nature or your (unqueryable) data source then you will want to
think about some type of intelligent caching to reduce the impact of
worst case OData queries. You might think about simply disabling
$orderby and $filter options (which is perfectly OK in OData). You can
do that by overriding the
set_orderby() and
set_filter() methods,
raising NotImplementedError.