4.2.2. A SQL-Backed Data Service¶
The sample code for this service is in the samples directory in the Pyslet distribution.
This project demonstrates how to construct a simple OData service based
on the SQLiteEntityContainer class.
We don’t need any customisations, this class does everything we need
‘out of the box’. Although we use SQLite by default, an implementation
is also provided using the MySQLdb adaptor. If you want to use a
database other than these you will need to create a new implementation
of the generic SQLEntityContainer. See
the reference documentation for sqlds for
details on what is involved. You shouldn’t have to change much!
4.2.2.1. Step 1: Creating the Metadata Model¶
If you haven’t read the Sample Project: InMemory Data Service yet it is a good idea to do that to get a primer on how providers work. The actual differences between writing a SQL-backed service and one backed by the in-memory implementation are minimal. I haven’t repeated code here if it is essentially the same as the code shown in the previous example, but remember that the full working source is available in the samples directory.
For this project, I’ve chosen to write an OData service that exposes weather data for my home town of Cambridge, England. The choice of data set is purely because I have access to over 340,000 data points stretching back to 1995 thanks to the excellent Weather Station website run by the University of Cambridge’s Digital Technology Group: http://www.cl.cam.ac.uk/research/dtg/weather/
We start with our metadata model, which we write by hand. There are two entity sets. The first contains the actual data readings from the weather station and the second contains notes relating to known inaccuracies in the data. I’ve included a navigation property so that it is easy to see which note, if any, applies to a data point.
Here’s the model:
<?xml version="1.0" encoding="utf-8" standalone="yes" ?>
<edmx:Edmx Version="1.0" xmlns:edmx="http://schemas.microsoft.com/ado/2007/06/edmx"
xmlns:m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata">
<edmx:DataServices m:DataServiceVersion="2.0">
<Schema Namespace="WeatherSchema" xmlns="http://schemas.microsoft.com/ado/2006/04/edm">
<EntityContainer Name="CambridgeWeather" m:IsDefaultEntityContainer="true">
<EntitySet Name="DataPoints" EntityType="WeatherSchema.DataPoint"/>
<EntitySet Name="Notes" EntityType="WeatherSchema.Note"/>
<AssociationSet Name="DataPointNotes" Association="WeatherSchema.DataPointNote">
<End Role="DataPoint" EntitySet="DataPoints"/>
<End Role="Note" EntitySet="Notes"/>
</AssociationSet>
</EntityContainer>
<EntityType Name="DataPoint">
<Key>
<PropertyRef Name="TimePoint"/>
</Key>
<Property Name="TimePoint" Type="Edm.DateTime" Nullable="false" Precision="0" m:FC_TargetPath="SyndicationUpdated" m:FC_KeepInContent="true"/>
<Property Name="Temperature" Type="Edm.Single" m:FC_TargetPath="SyndicationTitle" m:FC_KeepInContent="true"/>
<Property Name="Humidity" Type="Edm.Byte"/>
<Property Name="DewPoint" Type="Edm.Single"/>
<Property Name="Pressure" Type="Edm.Int16"/>
<Property Name="WindSpeed" Type="Edm.Single"/>
<Property Name="WindDirection" Type="Edm.String" MaxLength="3" Unicode="false"/>
<Property Name="WindSpeedMax" Type="Edm.Single"/>
<Property Name="SunRainStart" Type="Edm.Time" Precision="0"></Property>
<Property Name="Sun" Type="Edm.Single"/>
<Property Name="Rain" Type="Edm.Single"/>
<NavigationProperty Name="Note" Relationship="WeatherSchema.DataPointNote"
FromRole="DataPoint" ToRole="Note"/>
</EntityType>
<EntityType Name="Note">
<Key><PropertyRef Name="ID"></PropertyRef></Key>
<Property Name="ID" Type="Edm.Int32" Nullable="false"/>
<Property Name="StartDate" Type="Edm.DateTime" Nullable="false" Precision="0"/>
<Property Name="EndDate" Type="Edm.DateTime" Nullable="false" Precision="0"/>
<Property Name="Details" Type="Edm.String" MaxLength="1024" Nullable="false" FixedLength="false"/>
<NavigationProperty Name="DataPoints" Relationship="WeatherSchema.DataPointNote"
FromRole="Note" ToRole="DataPoint"/>
</EntityType>
<Association Name="DataPointNote">
<End Role="DataPoint" Type="WeatherSchema.DataPoint" Multiplicity="*"/>
<End Role="Note" Type="WeatherSchema.Note" Multiplicity="0..1"/>
</Association>
</Schema>
</edmx:DataServices>
</edmx:Edmx>
I’ve added two feed customisations to this model. The TimePoint field of the data point will be echoed in the Atom ‘updated’ field and the Temperature field will become the Atom title. This will make my OData service more interesting to look at in a standard browser.
As before, we’ll save the model to a file and load it when our script starts up.
To link the model to a SQLite database back-end we need to create an
instance of
SQLiteEntityContainer:
SAMPLE_DB='weather.db'
def make_container(doc, drop=False, path=SAMPLE_DB):
if drop and os.path.isfile(path):
os.remove(path)
create = not os.path.isfile(path)
container = SQLiteEntityContainer(
file_path=path,
container=doc.root.DataServices['WeatherSchema.CambridgeWeather'])
if create:
container.create_all_tables()
return doc.root.DataServices['WeatherSchema.CambridgeWeather']
This function handles the only SQL-specific part of our project. When we create a SQLite container we have to pass two keyword arguments: rather than just the container definition as we did for the in-memory implementation. We don’t need to return a value because the SQL implementation is bound to the model that was passed in doc.
The code above automatically creates the tables if the database doesn’t exist yet. This is fine if you are starting from scratch but if you want to expose an existing database you’ll need to work backwards from your existing schema when creating the model. Anyway, letting Pyslet create your SQL tables for you neglects your DBA who will almost certainly want to create indexes to optimise performance and tweak the model to get the best out of your platform. The automatically generated SQL script is supposed to be a starting point, not the complete solution.
For example, the data set I used for this project has over 300,000 records in it. At the end of this exercise I had an OData server capable of serving this information from a SQLite database but example URLs were taking 10s or more on my laptop to load. I created an index on the Temperature column using the SQLite command line and the page load times were instantaneous:
sqlite> create index TIndex ON DataPoints(Temperature);
4.2.2.1.1. Modelling an Existing Database¶
For simple data properties it should be fairly easy to map to the EDM. Here is the way Pyslet maps simple types in the EDM to SQL types:
| EDM Type | SQL Equivalent |
| Edm.Binary | BINARY(MaxLength) if FixedLength specified |
| Edm.Binary | VARBINARY(MaxLength) if no FixedLength |
| Edm.Boolean | BOOLEAN |
| Edm.Byte | SMALLINT |
| Edm.DateTime | TIMESTAMP |
| Edm.DateTimeOffset | CHARACTER(20), ISO 8601 string representation is used |
| Edm.Decimal | DECIMAL(Precision,Scale), defaults 10,0 |
| Edm.Double | FLOAT |
| Edm.Guid | BINARY(16) |
| Edm.Int16 | SMALLINT |
| Edm.Int32 | INTEGER |
| Edm.Int64 | BIGINT |
| Edm.SByte | SMALLINT |
| Edm.Single | REAL |
| Edm.String | CHAR(MaxLength) or VARCHAR(MaxLength) |
| Edm.String | NCHAR(MaxLength) or NVARCHAR(MaxLength) if Unicode=”true” |
| Edm.Time | TIME |
Navigation properties, and complex properties do not map as easily but they can still be modelled. To start with, look at the way the SQLite implementation turns our model into a SQL CREATE TABLE statement:
>>> import weather
>>> doc=weather.load_metadata()
>>> weather.make_container(doc)
>>> dataPoints=doc.root.DataServices['WeatherSchema.CambridgeWeather.DataPoints'].open()
>>> print dataPoints.create_table_query()[0]
CREATE TABLE "DataPoints" ("TimePoint" TIMESTAMP NOT NULL,
"Temperature" REAL, "Humidity" SMALLINT, "DewPoint" REAL, "Pressure"
SMALLINT, "WindSpeed" REAL, "WindDirection" TEXT, "WindSpeedMax"
REAL, "SunRainStart" REAL, "Sun" REAL, "Rain" REAL,
"DataPointNotes_ID" INTEGER, PRIMARY KEY ("TimePoint"), CONSTRAINT
"DataPointNotes" FOREIGN KEY ("DataPointNotes_ID") REFERENCES
"Notes"("ID"))
After all the data properties there’s an additional property called DataPointNotes_ID which is a foreign key into into the Notes table. This was created automatically to model the association set that links the two EntitySets in the container.
Pyslet generates foreign keys for the following types of association:
| 0..1 to 1 | With UNIQUE and NOT NULL constraints |
| * to 1 | With a NOT NULL constraint only |
| * to 0..1 | No additional constraints |
When these relationships are reversed the foreign key is of course created in the target table.
What if your foreign key has a different name, say, NoteID? Pyslet
gives you the chance to override all name mappings. To fix up this part
of the model you need to create a derived class of the base class
SQLEntityContainer and override the
mangle_name() method.
In this case, the method would have been called like this:
quotedName=container.mangle_name((u"DataPoints",u"DataPointNotes",u"ID"))
There is a single argument consisting of a tuple. The first item is the name of the EntitySet (SQL TABLE) and the subsequent items complete a kind of ‘path’ to the value. Foreign keys have a path comprising of the AssociationSet name followed by the name of the key field in the target EntitySet. The default implementation just joins the path with an underscore character. The method must return a suitably quoted value to use for the column name. To complete the example, here is how our subclass might implement this method to ensure that the foreign key is called ‘NoteID’ instead of ‘DataPointNotes_ID’:
def mangle_name(self,source_path):
if source_path==(u"DataPoints",u"DataPointNotes",u"ID"):
return self.quote_identifier(u'NoteID')
else:
return super(MyCustomerContainer,self).mangle_name(source_path)
You may be wondering why we don’t expose the foreign key field in the model. Some libraries might force you to expose the foreign key in order to expose the navigation property but Pyslet takes the opposite approach. The whole point of navigation properties is to hide away details like foreign keys. If you really want to access the value you can always use an expansion and select the key field in the target entity. Exposing it in the source entity just tempts you in to writing code that ‘knows’ about your model for example, if we had exposed the foreign key in our example as a simple property we might have been tempted to do something like this:
noteID=data_point['DataPointNotes_ID'].value
if noteID is not None:
note=noteCollection[noteID]
# do something with the note
When we should be doing something like this:
note=data_point['Note'].get_entity()
if note is not None:
# do something with the note
Complex types are handled in the same way as foreign keys, the path being comprised of the name(s) of the complex field(s) terminated by the name of a simple property. For example, if you have a complex type called Address and two properties of type Address called “Home” and “Work” you might end up with SQL that looked like this:
CREATE TABLE Employee (
...
Home_Street NVARCHAR(50),
Home_City NVARCHAR(50),
Home_Phone NVARCHAR(50),
Work_Street NVARCHAR(50),
Work_City NVARCHAR(50),
Work_Phone NVARCHAR(50)
...
)
You often see SQL written like this anyway so if you want to tweak the mapping to put a Complex type in your model you can.
Finally, we need to deal with the symmetric relationships, 1 to 1 and * to *. These are modelled by separate tables. 1 to 1 relationships are best avoided, the advantages over combining the two entities into a single larger entity are marginal given OData’s $select option which allows you to pick a subset of the fields anyway. If you have them in your SQL schema already you might consider creating a view to combine them before attempting to map them to the metadata model.
Either way, both types of symmetric relationships get mapped to a table
with the name of the AssociationSet. There are two sets of foreign
keys, one for each of the EntitySets being joined. The paths are rather
complex and are explained in detail in
SQLAssociationCollection.
4.2.2.2. Step 2: Test the Model¶
Before we add the complication of using our model with a SQL database, let’s test it out using the same in-memory implementation we used before:
def dry_run():
doc=load_metadata()
container=InMemoryEntityContainer(doc.root.DataServices['WeatherSchema.CambridgeWeather'])
weatherData=doc.root.DataServices['WeatherSchema.CambridgeWeather.DataPoints']
weather_notes=doc.root.DataServices['WeatherSchema.CambridgeWeather.Notes']
load_data(weatherData,SAMPLE_DIR)
load_notes(weather_notes,'weathernotes.txt',weatherData)
return doc.root.DataServices['WeatherSchema.CambridgeWeather']
SAMPLE_DIR here is the name of a directory containing data from the weather station. The implementation of the load_data function is fairly ordinary, parsing the daily text files from the station and adding them to the DataPoints entity set.
The implementation of the load_notes function is more interesting as it demonstrates use of the API for binding entities together using navigation properties:
def load_notes(weather_notes,file_name,weatherData):
with open(file_name,'r') as f:
id=1
with weather_notes.open() as collection, weatherData.open() as data:
while True:
line=f.readline()
if len(line)==0:
break
elif line[0]=='#':
continue
noteWords=line.split()
if noteWords:
note=collection.new_entity()
note['ID'].set_from_value(id)
start=iso.TimePoint(
date=iso.Date.from_str(noteWords[0]),
time=iso.Time(hour=0,minute=0,second=0))
note['StartDate'].set_from_value(start)
end=iso.TimePoint(
date=iso.Date.from_str(noteWords[1]).offset(days=1),
time=iso.Time(hour=0,minute=0,second=0))
note['EndDate'].set_from_value(end)
note['Details'].set_from_value(string.join(noteWords[2:],' '))
collection.insert_entity(note)
# now find the data points that match
data.set_filter(core.CommonExpression.from_str("TimePoint ge datetime'%s' and TimePoint lt datetime'%s'"%(unicode(start),unicode(end))))
for data_point in data.values():
data_point['Note'].bind_entity(note)
data.update_entity(data_point)
id=id+1
with weather_notes.open() as collection:
collection.set_orderby(core.CommonExpression.orderby_from_str('StartDate desc'))
for e in collection.itervalues():
with e['DataPoints'].open() as affectedData:
print "%s-%s: %s (%i data points affected)"%(unicode(e['StartDate'].value),
unicode(e['EndDate'].value),e['Details'].value,len(affectedData))
The function opens collections for both Notes and DataPoints. For each uncommented line in the source file it creates a new Note entity, then, it adds a filter to the collection of data points that narrows down the collection to all the data points affected by the note and then iterates through them binding the note to the data point and updating the entity (to commit the change to the data source). Here’s a sample of the output on a dry-run of a small sample of the data from November 2007:
2007-12-25T00:00:00-2008-01-03T00:00:00: All sensors inaccurate (0 data points affected)
2007-11-01T00:00:00-2007-11-23T00:00:00: rain sensor over reporting rainfall following malfunction (49 data points affected)
You may wonder why we use the values function, rather than itervalues in the loop that updates the data points. itervalues would certainly have been more efficient but, just like native Python dictionaries, it is a bad idea to modify the data source when iterating as unpredictable things may happen. The concept is extended by this API to cover the entire container: a thread should not modify the container while iterating through a collection.
Of course, this API has been designed for parallel use so there is always the chance that another thread or process is modifying the data source outside of your control. Behaviour in that case is left to be implementation dependent - storage engines have widely differing policies on what to do in these cases.
If you have large amounts of data to iterate through you should consider using list(collection.iterpage(True)) instead. For a SQL data souurce this has the disadvantage of executing a new query for each page rather than spooling data from a single SELECT but it provides control over page size (and hence memory usage in your client) and is robust to modifications.
As an aside, if you change the call from values to itervalues in the sample you may well discover a bug in the SQLite driver in Python 2.7. The bug means that a commit on a database connection while you are fetching data on another cursor causes subsequent data access commands to fail. It’s a bit technical, but the details are here: http://bugs.python.org/issue10513
Having tested the model using the in-memory provider we can implement a full test using the SQL back-end we created in make_container above. This test function prints the 30 strongest wind gusts in the database, along with any linked note:
def test_model(drop=False):
doc=load_metadata()
container=make_container(doc,drop)
weatherData=doc.root.DataServices['WeatherSchema.CambridgeWeather.DataPoints']
weather_notes=doc.root.DataServices['WeatherSchema.CambridgeWeather.Notes']
if drop:
load_data(weatherData,SAMPLE_DIR)
load_notes(weather_notes,'weathernotes.txt',weatherData)
with weatherData.open() as collection:
collection.set_orderby(core.CommonExpression.orderby_from_str('WindSpeedMax desc'))
collection.set_page(30)
for e in collection.iterpage():
note=e['Note'].get_entity()
if e['WindSpeedMax'] and e['Pressure']:
print "%s: Pressure %imb, max wind speed %0.1f knots (%0.1f mph); %s"%(unicode(e['TimePoint'].value),
e['Pressure'].value,e['WindSpeedMax'].value,e['WindSpeedMax'].value*1.15078,
note['Details'] if note is not None else "")
Here’s some sample output:
>>> weather.test_model()
2002-10-27T10:30:00: Pressure 988mb, max wind speed 74.0 knots (85.2 mph);
2004-03-20T15:30:00: Pressure 993mb, max wind speed 72.0 knots (82.9 mph);
2007-01-18T14:30:00: Pressure 984mb, max wind speed 70.0 knots (80.6 mph);
... [ and so on ]
...
2007-01-11T10:30:00: Pressure 998mb, max wind speed 58.0 knots (66.7 mph);
2007-01-18T07:30:00: Pressure 980mb, max wind speed 58.0 knots (66.7 mph);
1996-02-18T04:30:00: Pressure 998mb, max wind speed 56.0 knots (64.4 mph); humidity and dewpoint readings may be inaccurate, particularly high humidity readings
2000-12-13T01:30:00: Pressure 991mb, max wind speed 56.0 knots (64.4 mph);
2002-10-27T13:00:00: Pressure 996mb, max wind speed 56.0 knots (64.4 mph);
2004-01-31T17:30:00: Pressure 983mb, max wind speed 56.0 knots (64.4 mph);
Notice that the reading from 1996 has a related note.
4.2.2.3. Step 4: Link the Data Source to the OData Server¶
This data set is designed to be updated by some offline process that
polls the weather station for the latest readings and adds them to the
database behind the scenes. Unlike the memory-cache example, the OData
interface should be read-only so we use the
ReadOnlyServer sub-class of the OData
server:
def run_weather_server(weather_app=None):
"""Starts the web server running"""
server=make_server('',SERVICE_PORT,weather_app)
logging.info("HTTP server on port %i running"%SERVICE_PORT)
# Respond to requests until process is killed
server.serve_forever()
def main():
"""Executed when we are launched"""
doc=load_metadata()
container=make_container(doc)
server=ReadOnlyServer(serviceRoot=SERVICE_ROOT)
server.SetModel(doc)
t=threading.Thread(target=run_weather_server,kwargs={'weather_app':server})
t.setDaemon(True)
t.start()
logging.info("Starting HTTP server on %s"%SERVICE_ROOT)
t.join()
Once the script is running we test in a browser. I’ve loaded the full data set into the server, how many data points? Here’s how we can find out, in our browser we go to:
http://localhost:8080/DataPoints/$count
The result is 325213. Firefox recognises that the feeds are in Atom format and renders the feed customisations we made earlier.
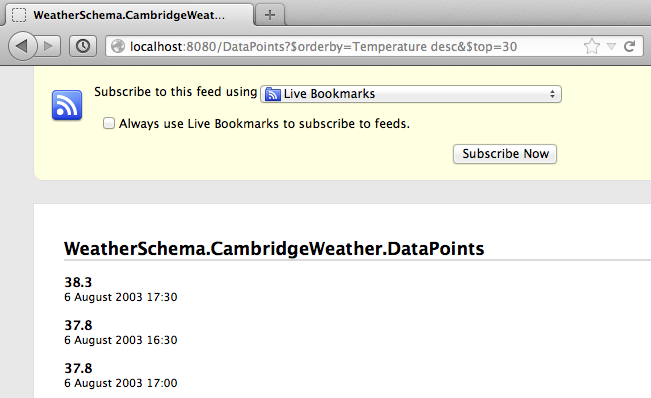
When we access this page with logging turned up to INFO we get the following output on the console, interspersed with the simple HTTP server output:
INFO:root:SELECT COUNT(*) FROM "DataPoints"; []
127.0.0.1 - - [21/Feb/2014 22:57:01] "GET /DataPoints/$count HTTP/1.1" 200 6
INFO:root:SELECT "TimePoint", "Temperature", "Humidity", "DewPoint", "Pressure", "WindSpeed", "WindDirection", "WindSpeedMax", "SunRainStart", "Sun", "Rain", "Temperature" AS o_1, "TimePoint" FROM "DataPoints" ORDER BY o_1 DESC, "TimePoint" ASC; []
127.0.0.1 - - [21/Feb/2014 22:57:18] "GET /DataPoints?$orderby=Temperature%20desc&$top=30 HTTP/1.1" 200 31006
You may wonder what those square brackets are doing at the end of the SQL statements. They’re actually used for logging the parameter values when the query has been parameterised. If we add a filter you’ll see what they do:
http://localhost:8080/DataPoints?$filter=Temperature%20gt%20-100&$orderby=Temperature%20asc&$top=30
And here’s the output on the console:
INFO:root:SELECT "TimePoint", "Temperature", "Humidity", "DewPoint", "Pressure", "WindSpeed", "WindDirection", "WindSpeedMax", "SunRainStart", "Sun", "Rain", "Temperature" AS o_1, "TimePoint" FROM "DataPoints" WHERE ("Temperature" > ?) ORDER BY o_1 DESC, "TimePoint" ASC; [-100]
127.0.0.1 - - [21/Feb/2014 16:35:09] "GET /DataPoints?$filter=Temperature%20gt%20-100&$orderby=Temperature%20desc&$top=30 HTTP/1.1" 200 31006
Yes, all Pyslet queries are fully parameterized for security and performance!